更多CG新聞
MORE CG News
Google Launches Nano Banana 2 Lite and Gemini Omni Flash Models for Creators
【Google發表 Nano Banana 2 Lite及Gemini Omni Flash 創作者雙模型】
Google DeepMind 日前正式宣佈推出兩款專為媒體生成而設的全新 AI 模型.
– Nano Banana 2 Lite (gemini-3.1-flash-lite-image) 影像模型, 主打超低延遲與高性價比, Text-to-image 輸出僅需 4 秒, 每千張 1K 影像成本低至 $0.034 美元, 極適合需要快速反覆測試的視覺pipeline.
– 另一方面 , 具備原生影片生成與對話式編輯能力的 Gemini Omni Flash (gemini-omni-flash-preview)正式向開發者開放.
該模型能結合文字、圖片與影片進行多模態參照, 精準維持場景一致性,影片輸出定價為每秒 $0.10 美元. 創作者可將兩者串聯, 先以 Nano Banana 2 Lite 生成靜態參考圖, 再經由 Gemini Omni Flash 動態化為高質素影片, 為內容創造提供極速、低成本的端到端多媒體工作流程.
AI Studio Official Launch: iClone Personal FREE for all users
【Reallusion推出免費iClone個人版!內建AI Studio實現精準3D to AI創作】
Reallusion 早前推出「iClone Personal Edition」, 並向所有用戶免費開放, 同時全面整合強大的 AI Studio 工具, 創造全新的 3D 與 AI 混合工作流程 .
此版本完整解鎖了 iClone 的 3D 動態工具, 創作者能自由進行角色身體與面部動畫、精準口型同步, 並利用 AI 影片動態捕捉技術將真實畫面轉為 3D 動態.
全新的 iClone 個人版正式取代舊有的 30 天試用期, 創作者能無時間限制地在軟件內進行場景佈局、角色動態設計與無限次 Render, 預計於 7 月下旬開啟 Open Beta 的 RTX Render 引擎, 更讓用戶無需匯出即可在內部完成高品質 Render !!
正式上市的 AI Studio 帶來大幅升級, 重新設計的 AI 演員技術能精準鎖定角色特徵, 消除角度轉變時的身份漂移問題.
配合 Seedance 2.0 影片生成模型, 創作者可混合影像、音訊與 3D 鏡頭控制, 無需初始首Frame即可精準引導 AI 生成極具結構精確度的電影級畫面.
目前安裝更可直接獲得 500 免費 AI 點數, 讓個人創作者即時體驗全新工作流程.
CSD AI Video Sparks HK’s New Fan-Art Playground
【政府AI禁毒宣傳短片《Obsession 糖衣陷阱》引全港AI生成熱潮】
上星期五, 香港懲教署趁於「國際禁毒日」推出一段禁毒宣傳短片《Obsession 糖衣陷阱》, 利用AI人工智能生成「女團MV」, 引起網民熱議, 雖然相關影片最後需要兩度下架 .但”AI生成”的熱度卻令全港燒得熾熱 !!
片中四位 AI 生成的虛擬偶像——可樂、草草、冰兒 及 小悠 並未隨影片下架而淡出 . 相反, 她們精緻的造型激發了本地創作者的靈感, 迅速成為全港 AI 二次創作的全新練習場.
不少創作者藉此進行 AI 訓練, 為本地 AI 創作生態注入了意料之外的玩味與技術交流 !!
(非官方 – 鳩gen AI生成影片)
ByteDance Unveils Seedance 2.5 with 30-Second Native 4K AI Video Generation
【字節跳動發表 Seedance 2.5!支援 30 秒單鏡頭 AI 影片生成與原生 4K 輸出】
字節跳動(ByteDance)於火山引擎 FORCE 大會上, 正式發表全新 AI 影片生成模型Seedance 2.5 .
本次升級的核心重點在於突破性的「30 秒單鏡頭(one-shot)影片生成」能力, 能直接創造長達 30 秒的連續畫面, 免去後期剪輯拼湊的繁瑣程序.
Seedance 2.5 在可控性上大幅提升, 支援高達 50 個包含圖像、音訊及 3D assets 的全模態參考素材輸入. 能精確鎖定複雜動態下的角色與視覺風格一致性.
新版本更具備原生 4K 解析度輸出、10-bit 色深, 並將音訊與視覺信號整合於同一空間, 實現精確的口型同步. 目前該模型已展開全球企業內測, 預計將於 7 月初正式登陸即夢(Dreamina)及剪映(CapCut)等平台
Luma Introduces Ray 3.2 Video Gen AI with EXR Support
【Luma發布Ray 3.2影片生成AI與API,支援EXR輸出】
LLuma 正式發布最新影片生成 AI 模型「Ray 3.2」及相關 API,全面進軍專業影視製作市場. 新版本打破以往 AI 生成的隨機性,創造出讓創作者能以「Frame」為單位精確主導的專業工具 !
重點包括 :
– Frame-level Control with multi-keyframe:Ray 3.2 支援在單一影片片段(Clip)中加入高達 16 個Keyframes . 導演和製作團隊可以像畫 Storyboard 一樣, 精確引導鏡頭軌跡、畫面動態與敘事節奏, 徹底擺脫以往 AI 生成的隨機性.
– 完美保留動態與表情:提升了動態追蹤與面部表情性能. 能同時追蹤高達 8 張面孔 的細微表情與骨骼肢體動作, 確保角色的情緒在每幀之間保持連貫.
– 無縫對接專業 Pipeline:原生支援 HDR 生成與 16-bit EXR 格式匯出. 生成的高動態範圍畫面可直接放入現有的 Post-production、VFX 特效及 Color Grading 工作流程, 方便合成, 不損失畫質.
– 靈活重構畫面(Reframe):增強了 Reframe 功能, 容許後期製作人員在完全保留原始 Lighting 的前提下, 自由延伸畫面、替換背景或更改影片Aspect Ratios, 以適應不同平台, 避免重新生成.
– 長片生成與全面開放 API:支援生成高達 20 秒、1080p 的電影級長鏡頭, 同時 Luma 首次將 Ray 3.2 的完整控制介面開放為 API, 方便 Studio 或開發者直接整合至現有的內部工具或 Render farm 系統中.
x.AI Releases Grok Imagine 1.5 Video Generation Model Preview
【Grok Imagine 1.5影片生成預覽】
x.AI 正式發表最新圖像生成影片模型 grok-imagine-video-1.5-preview, 目前已透過 xAI API 開放預覽 .
這款新模型能將單張靜態圖片轉化為具電影感的流暢影片, 最高支援 720p 解像度.
用戶只需提供一張初始畫面並輸入自然語言提示詞, 即可精準控制鏡頭移動、動態節奏及音效設計. 該模型的優勢在於能完美保留原圖的細節與光影, 而非重新詮釋畫面.
此外它亦支援序列生成, 創作者可將多個分鏡串聯成更長的場景, 並在整個項目中保持視覺風格的一致性.
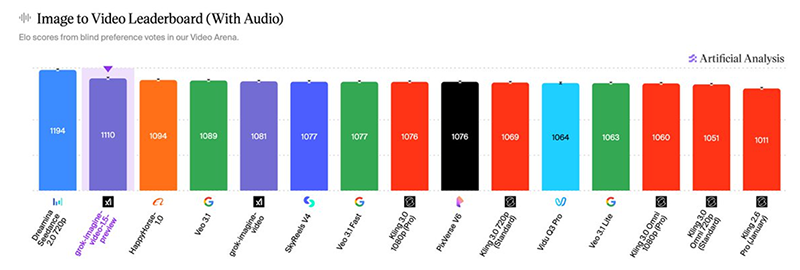
而根據獨立分析機構 Artificial Analysis 的「Video Arena(有聲版)」測試 Grok Imagine 1.5 Preview 獲得全球第 2 名, 僅次於字節跳動的 Seedance 2.0。而在無聲版測試中則排名第 3名,
評測影片顯示, 該模型在處理光影細節、連續複雜動作及物理法則上表現極為出色, 甚至超越了 Google 的 Veo 3.1.
目前開發者已可透過幾行程式碼將其整合至工作流程之中.
Runway Introduces MCP Support for Direct Generation in AI Agents
【Runway正式發布「Runway MCP」功能】
Runway 正式支援 Model Context Protocol (MCP) 協議, 將強大的影像生成能力深度整合至用戶的日常工作流.
現在開發者與設計師只需透過 Claude Desktop 或 Cursor 等外部 AI Agent, 即可在統一的對話界面中直接調用 Runway 最新模型(包括Gen-4.5及其他AI生片模型, 如Seedance 2.0)來創造高質素圖像及影片.
這項更新簡化了素材生成流程, 讓 AI 輔助創作成為開發與設計環境中不可或缺的一部分.
開發者與設計師在撰寫 Prompt 或代碼時, 無須離開原有的軟件界面, 即可呼叫 Runway 進行圖影生成.
無論是進行 UI 原型製作還是需要即時調整 3D assets 並進行 Render, Runway MCP 均能大幅提升執行效率並節省溝通時間.
目前相關協議已正式開放予開發者使用.
Google I/O 2026: Gemini Omni “World Model” Debuts
【Google I/O 2026:Gemini Omni 世界模型重磅登場 !!】
在今日舉行的 Google I/O 2026 大會上 , Google 展現了從「AI 工具」進化為「AI 代理(Agents)」的野心, Google 推出了多項突破性功能,特別是全新的 Gemini Omni 世界模型 !
Google 發表了全新的 Gemini Omni 模型, 真正的多模態生成(Multi-modal World Model):
不同於以往單純的文字轉影片, Gemini Omni 支援「任何輸入轉任何輸出」, 可以同時使用 文字、圖片、音訊或影片 作為提示詞來生成內容 .
Gemini Omni 能理解現實世界的物理規則, 生成的影片在物體運動、光影與環境互動上更加科學精確(如大會展示的氨基酸 3D 動畫).
對話式影片編輯(Conversational Editing): 這是一個重磅功能!影片生成後, 以直接透過對話修改內容.
Gemini Omni Flash: 即日起開放給 Google AI Plus、Pro 及 Ultra 訂閱者使用
其他還有 – AI 圖片生成與設計:Google Pics , 新一代的高速模型 Gemini 3.5 Flash 以及 個人 AI 代理 Gemini Spark 等等 …